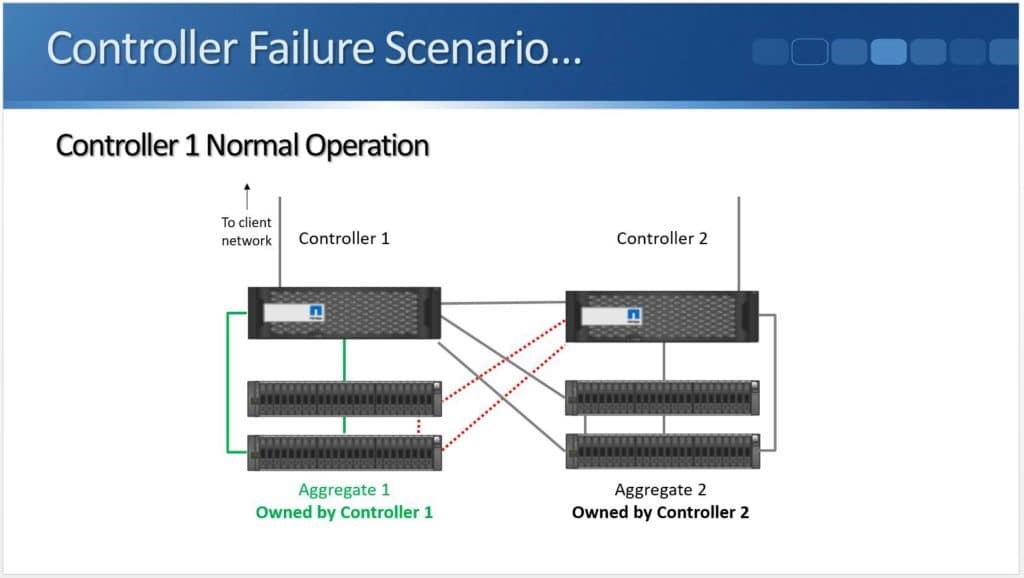
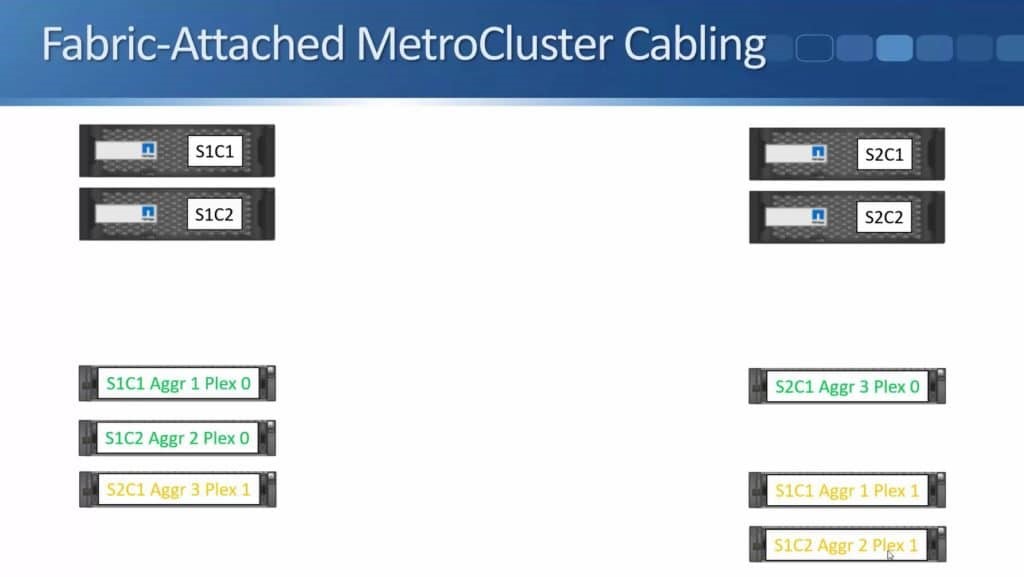
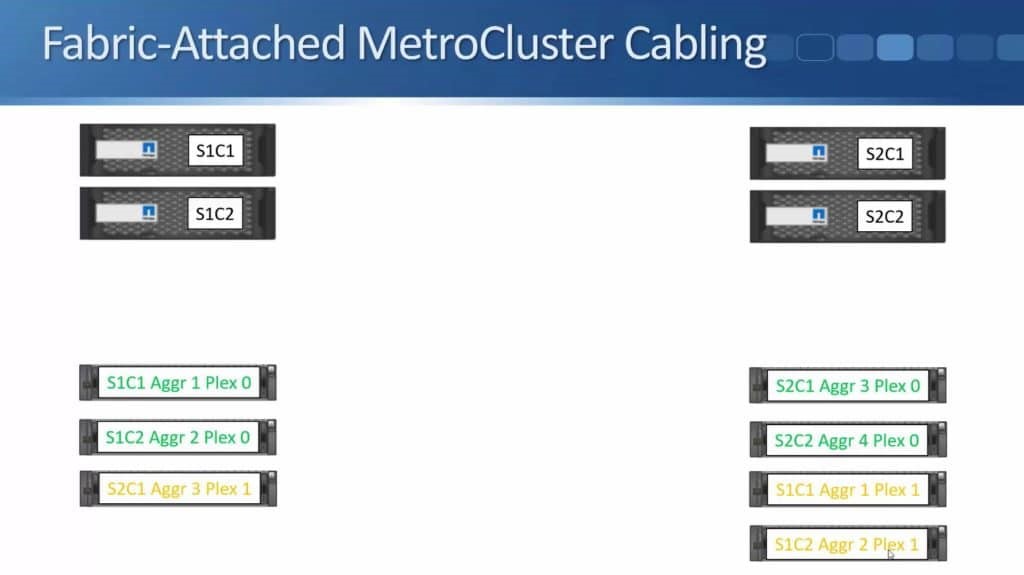
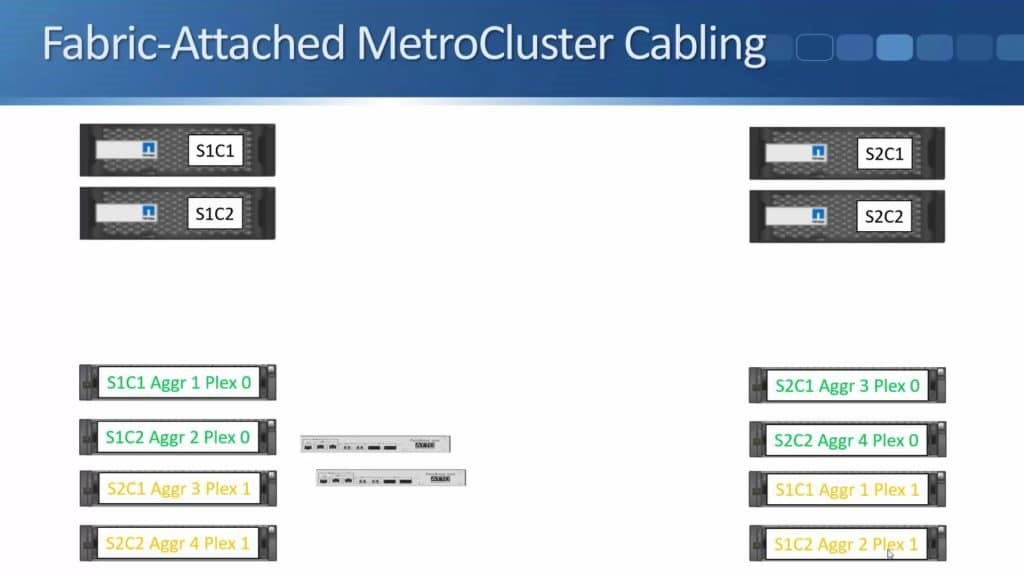
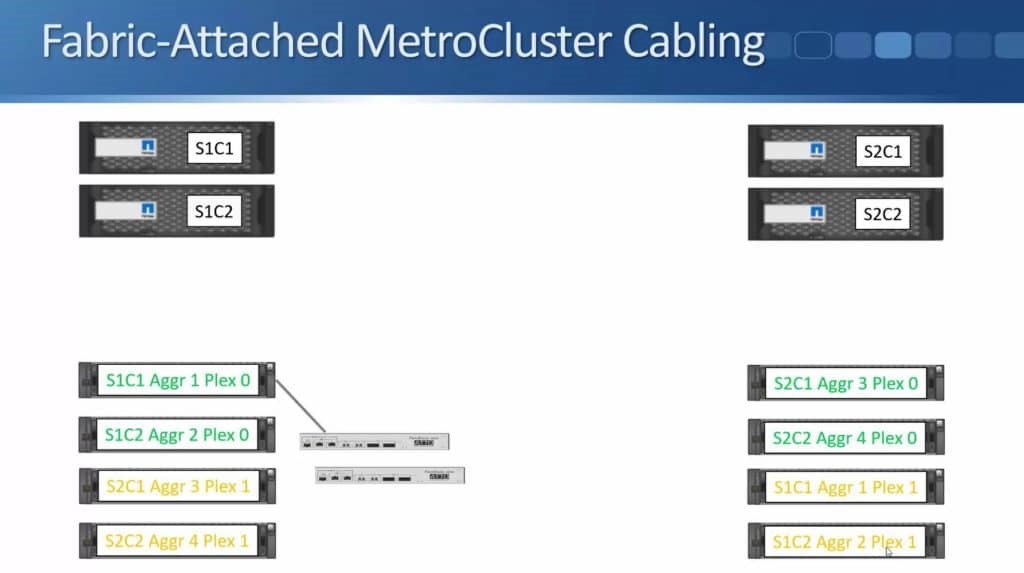
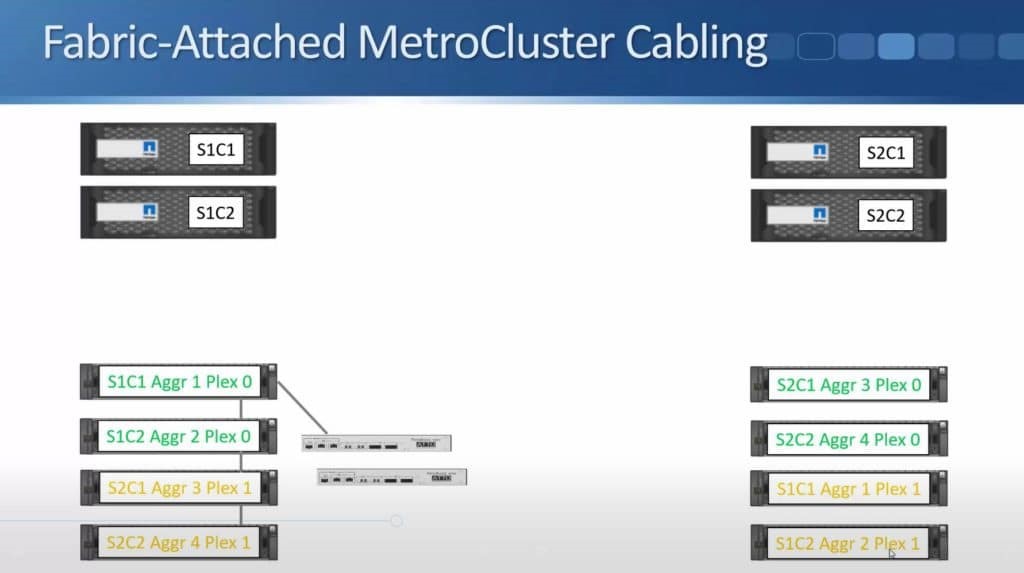
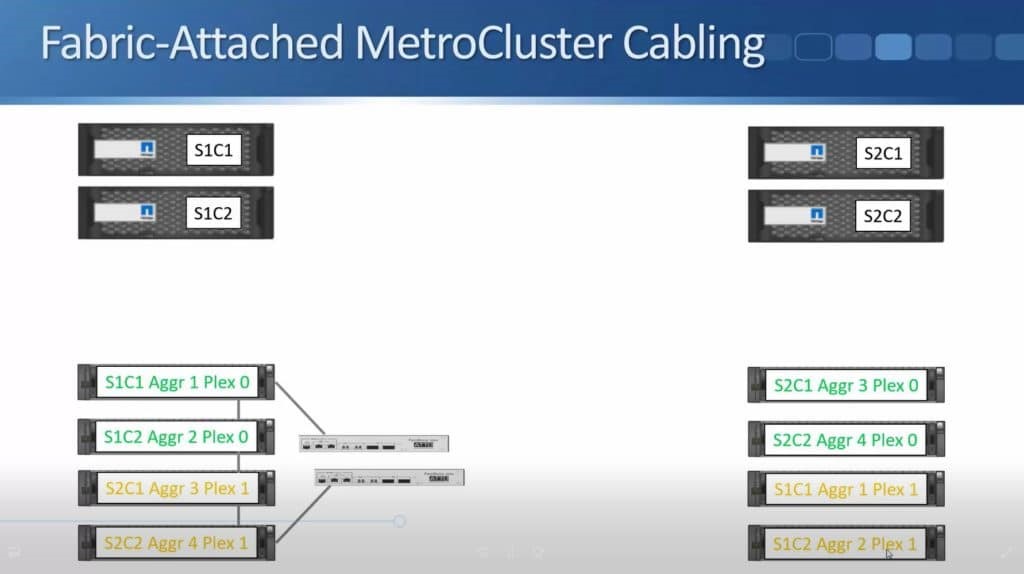
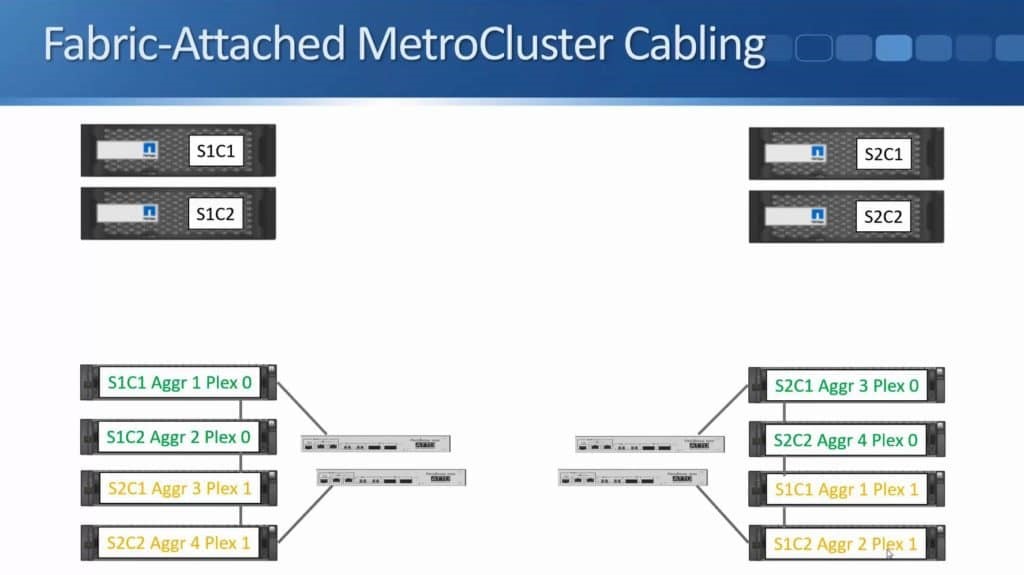
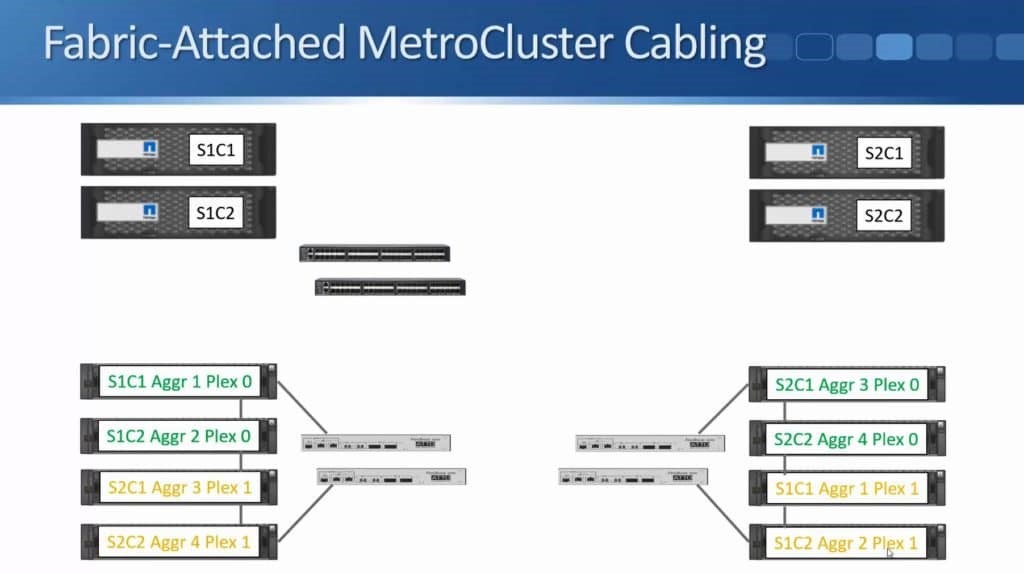
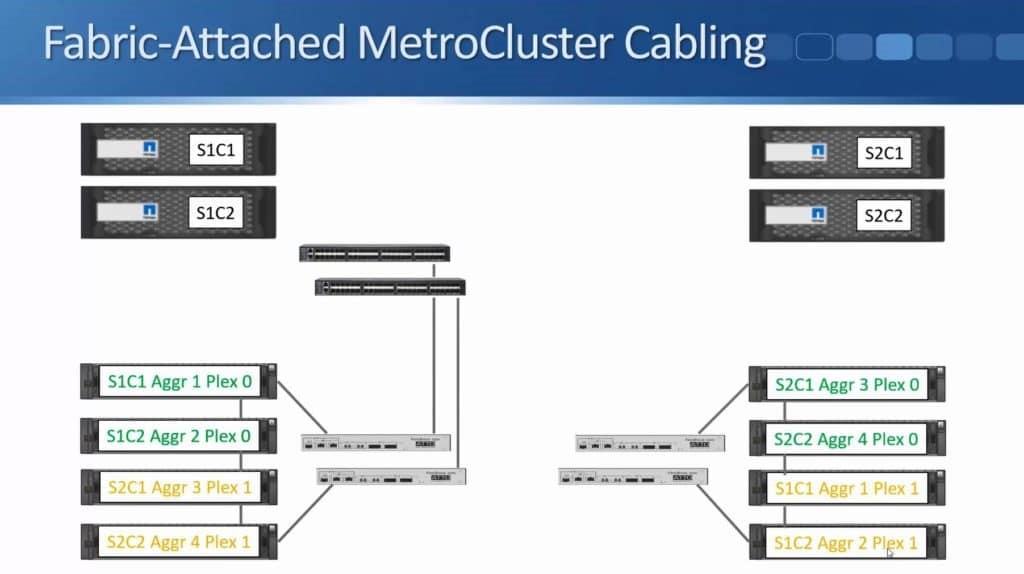
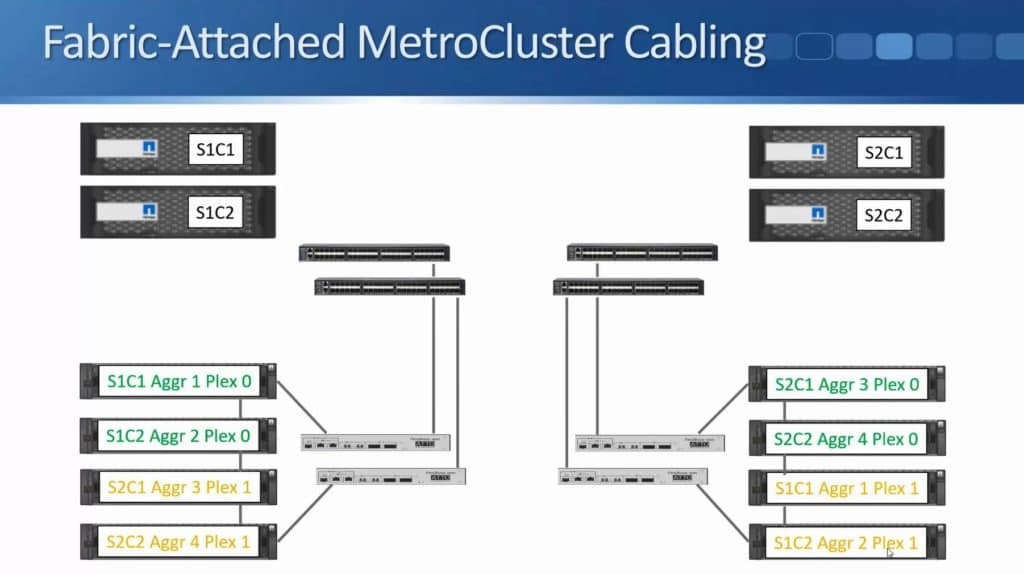
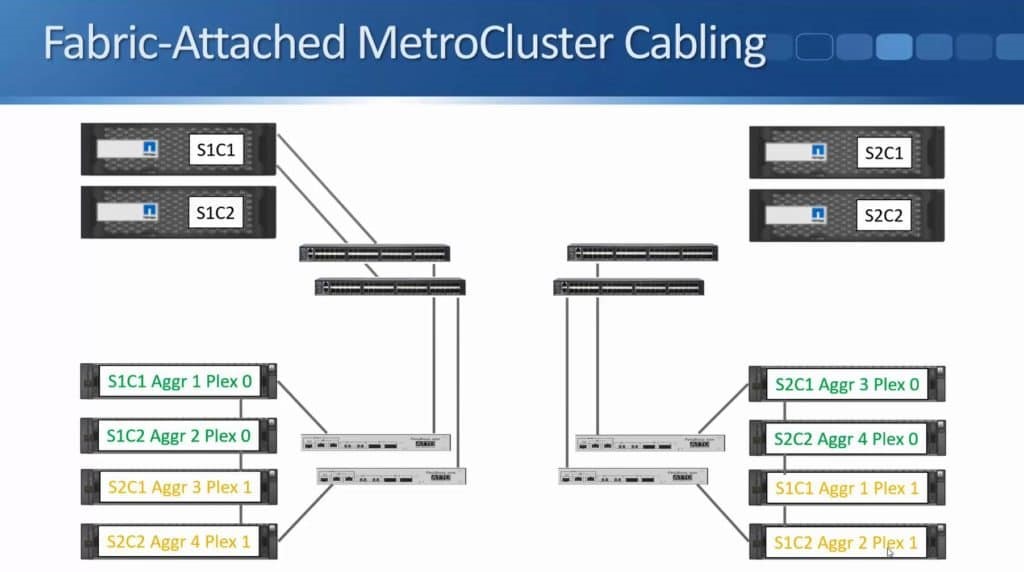
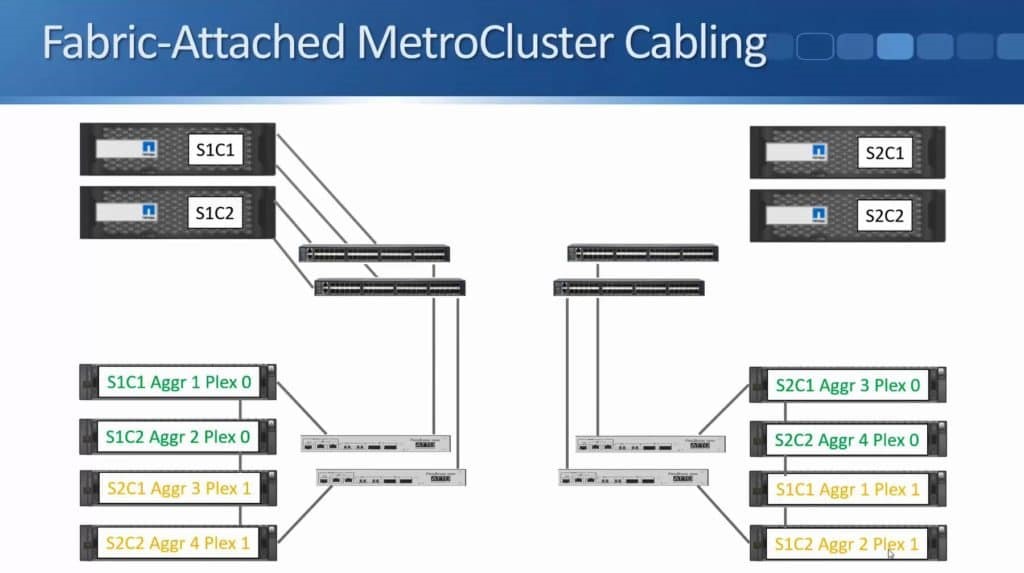
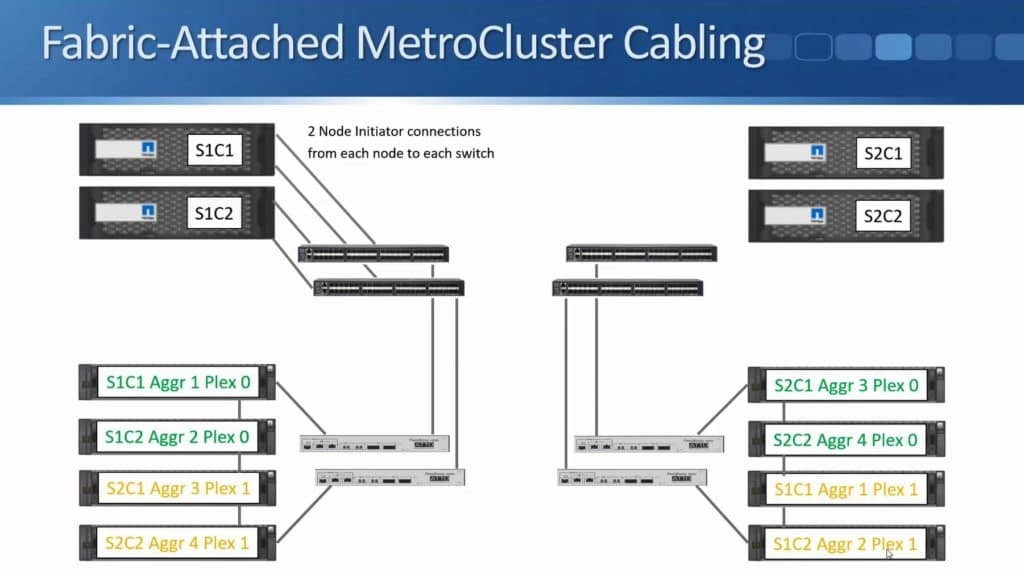
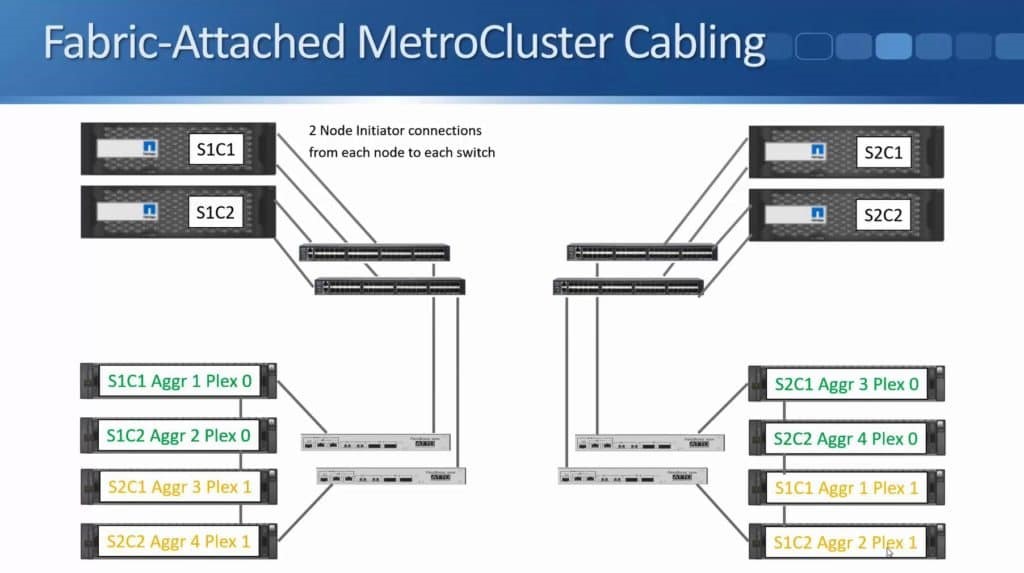
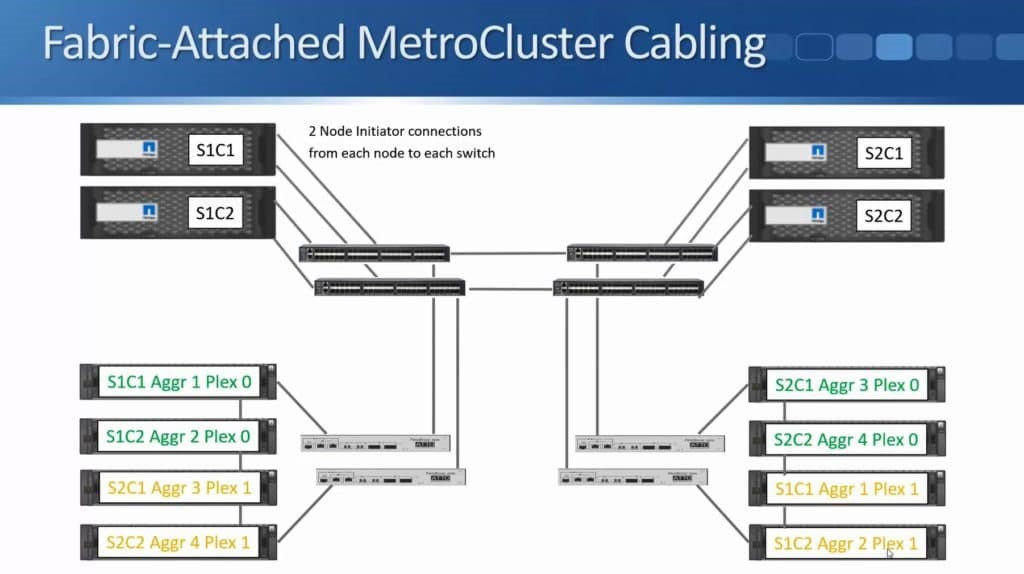
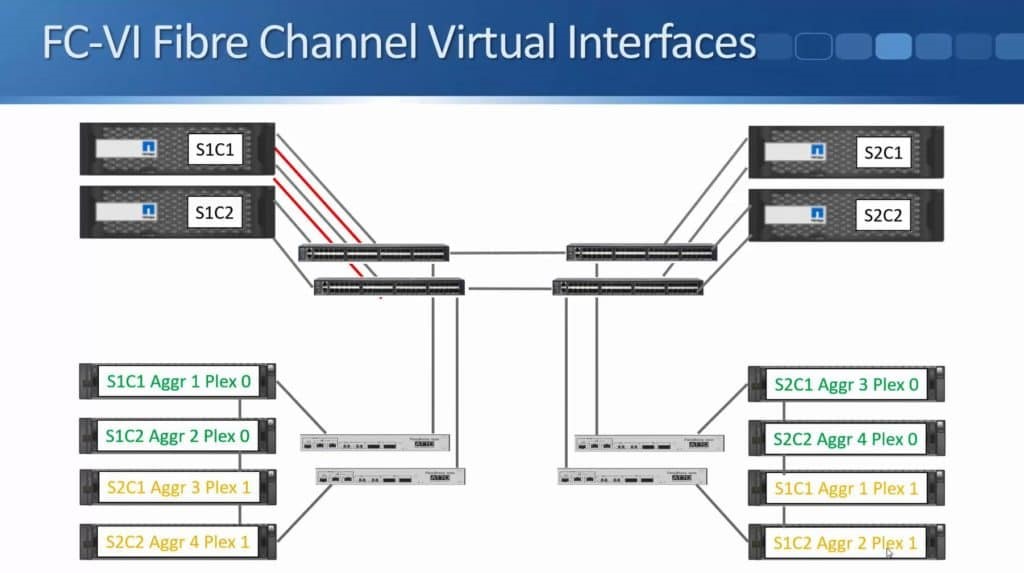
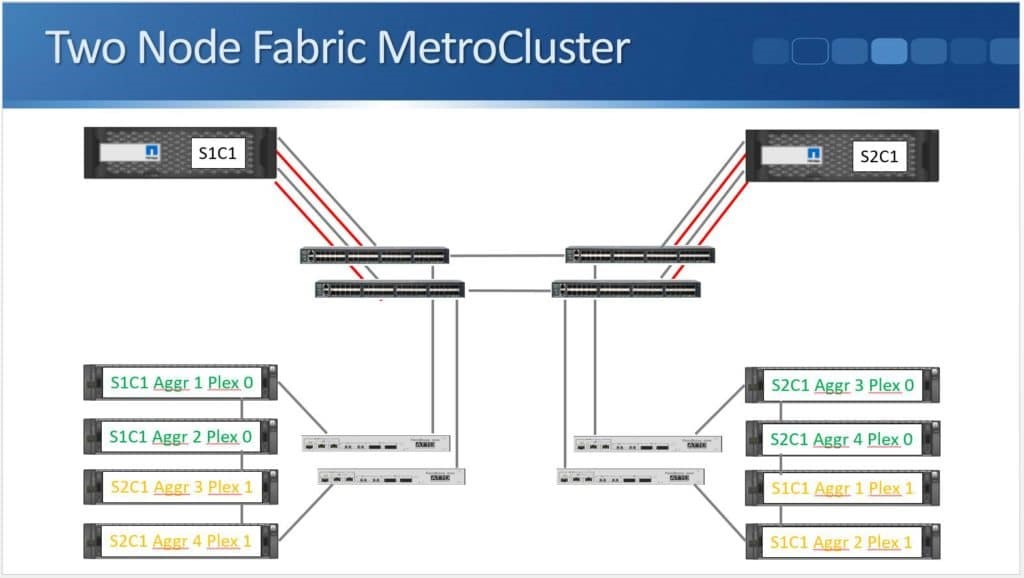
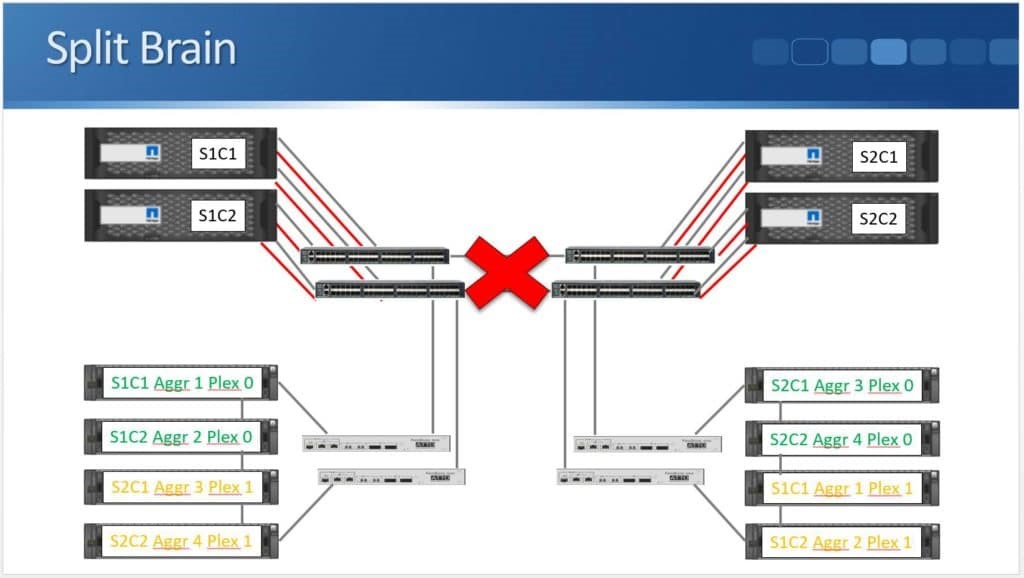
After months of teasing that synchronous replication was coming, Nimble has finally delivered the capabilities to customers. HPE announced the new capability this week during HPE Discover in Madrid, but it went beyond simple replication in the same announcement. HPE also enabled the ability to do metro clustering between Nimble storage arrays in the same release.
On launch, Peer Persistence on Nimble will allow for Microsoft SQL workloads on Windows server and VMware vSphere workloads to do seamless failover between two arrays in synchronous distances. Future releases will enhance support and an Oracle certification expected soon after release.
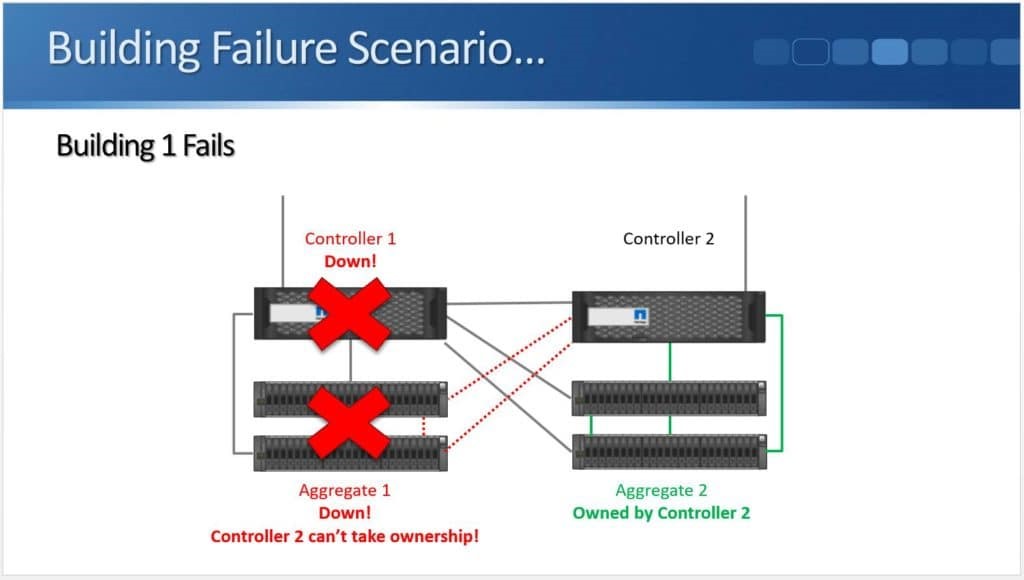
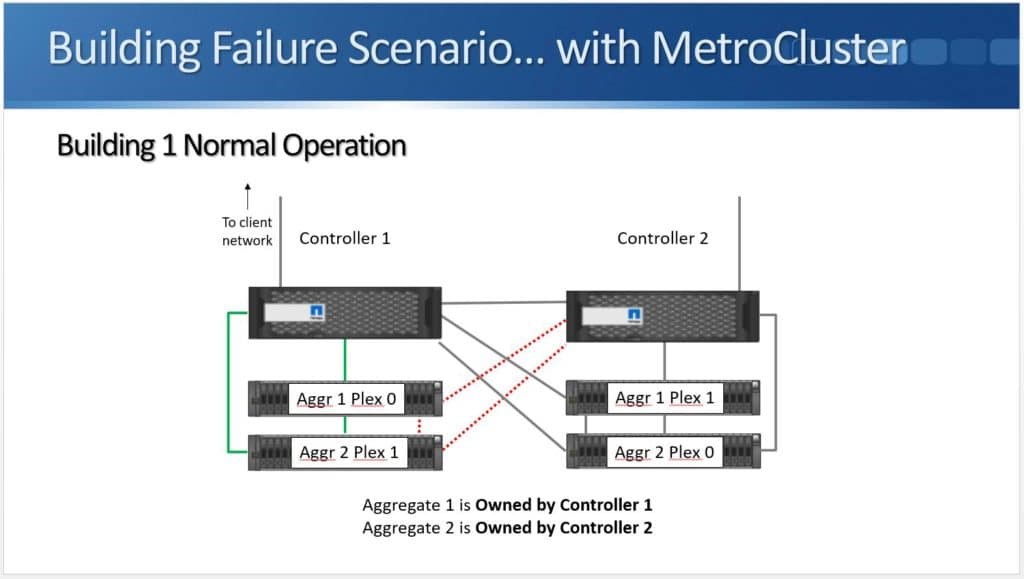
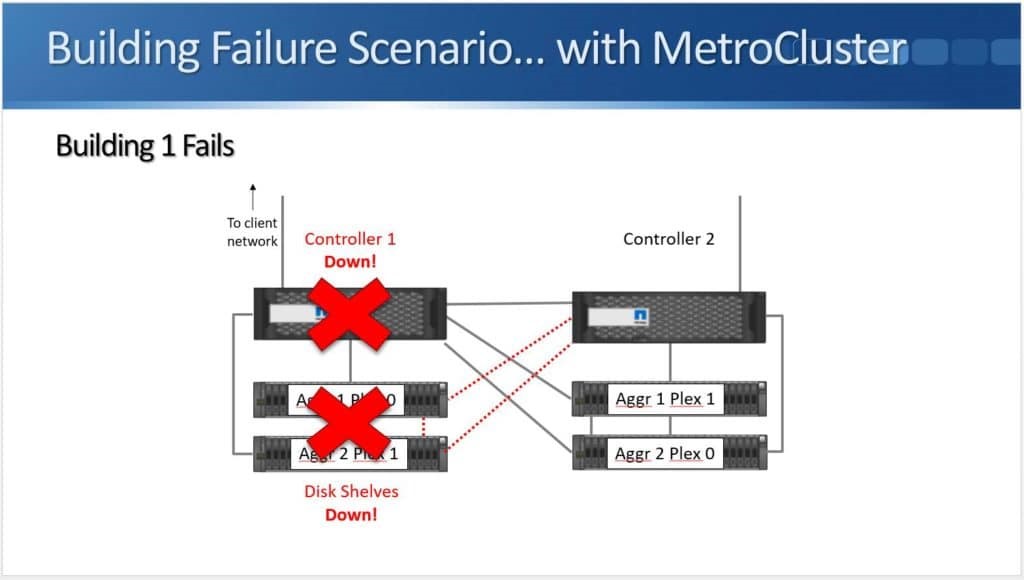
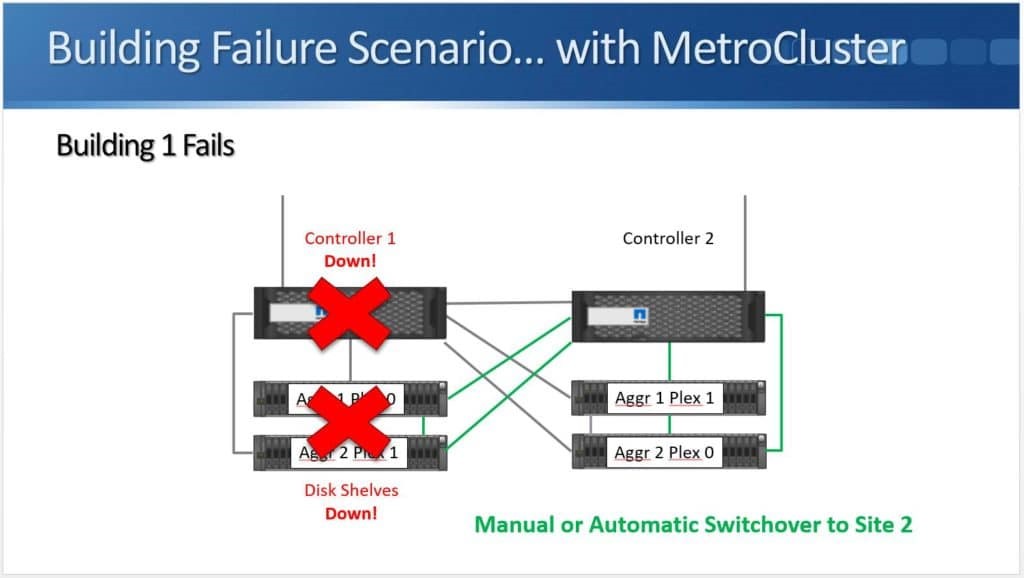
Peer Persistence is useful for critical workloads where customers want to eliminate the fault domain of a single storage array. This type of single point of failure is sometimes viewed as unavoidable and so arrays are architected to have lots of resiliency to mitigate the risk. Environmental issues (power, cooling, etc.) and even a bad code release (yes, they do happen) could put a critical system at risk for downtime and a costly outage, however metro storage clusters allow a pair of arrays to work together to protect workloads.
What is Peer Persistence?
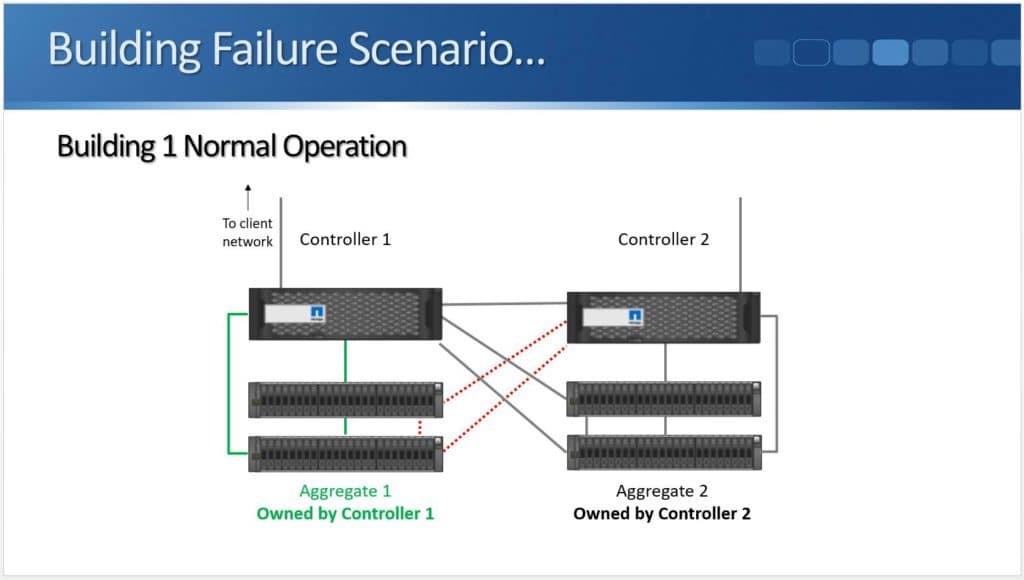
Peer Persistence is a branding for metro-storage clustering technology within the HPE line of storage. First delivered on 3PAR in 2013, Peer Persistence allows synchronous replication to seamlessly switch between two arrays – enabling failover between arrays for site protection or for fault domain protection within a datacenter.
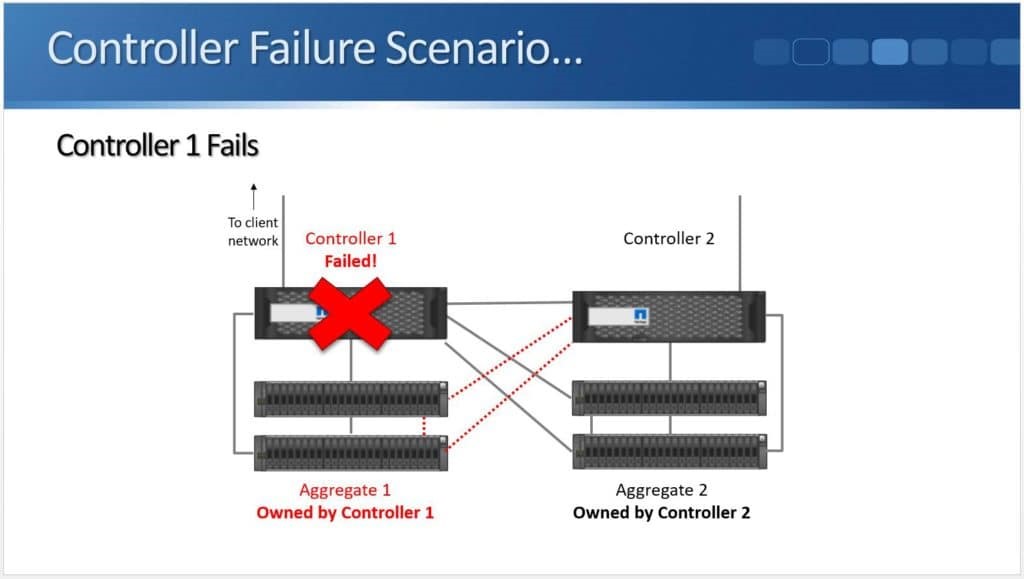
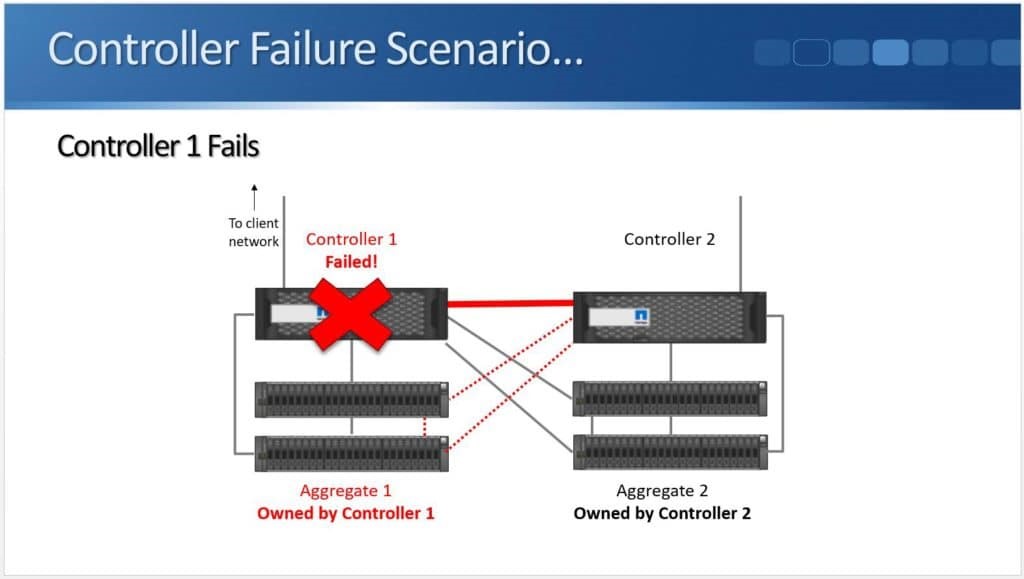
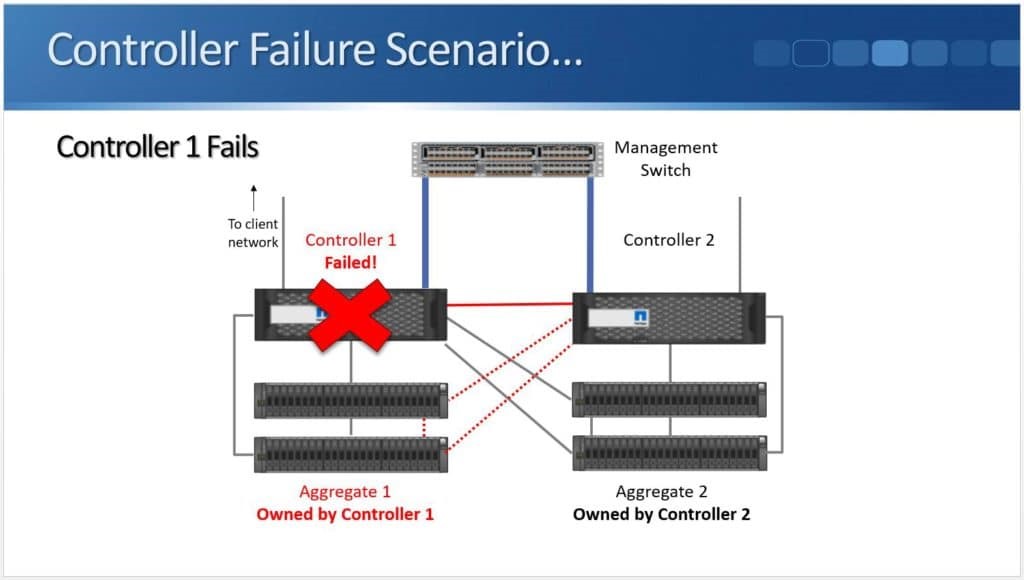
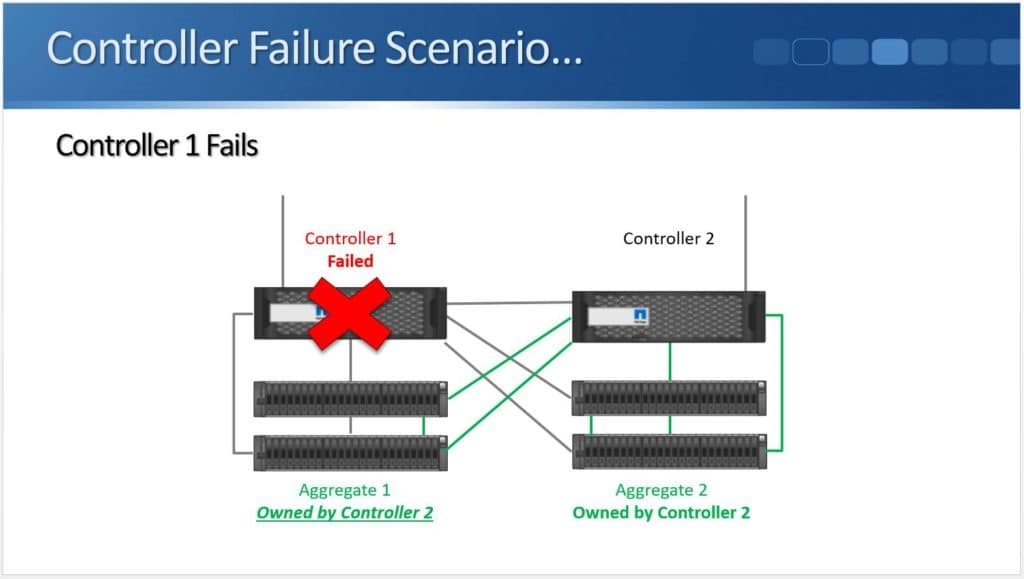
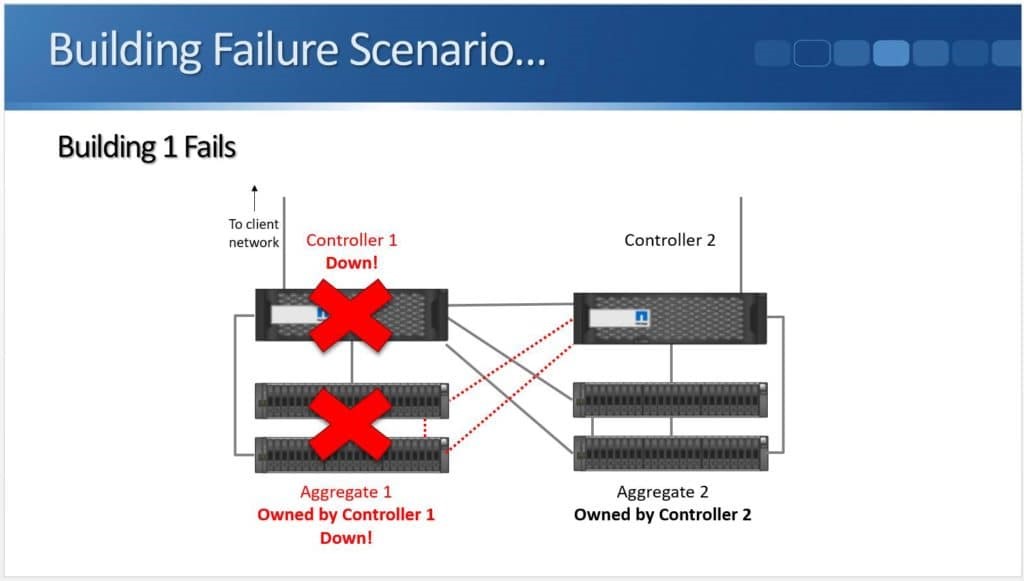
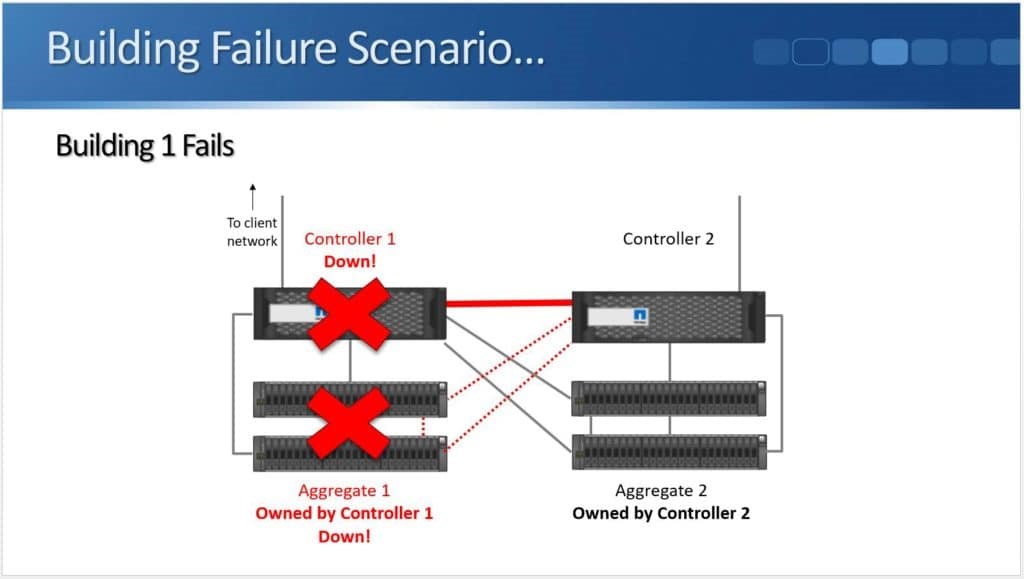
Within the SCSI stack, ALUA signals active and standby paths to the compute nodes to allow it to know which are the preferred paths and which are unavailable. In a 3PAR configuration, the standby paths represent the paths to the secondary storage array that is in read-only mode during synchronous replication. When a failure occurs on a primary array, an arbitration/quorum node allows the secondary node to come online as the primary and continue to accept IO without interruption. A SCSI signal is sent over the bus to the compute node and lets it know that the active paths have now moved to standby and the standby paths are now active. Internal OS queues hold any IO in transit at the time of the failover.
After a failure occurs, the quorum operation will dictate which array is in control. If the failure is repaired, the array comes back into the replication relationship and the data is synchronized between the arrays. The repaired array becomes the secondary and its paths are re-added to the host through a SCSI rescan.
See more?
If you want to see more about Peer Persistence on HPE Nimble storage, take a look at Calvin Zito’s ChalkTalk about the topic on YouTube.